




[November 20, 2018]
Shield AI Fundamentals: On Reinforcement Learning
A conversation with Evan Gravelle, an AI Engineer at Shield AI.
What is reinforcement learning?
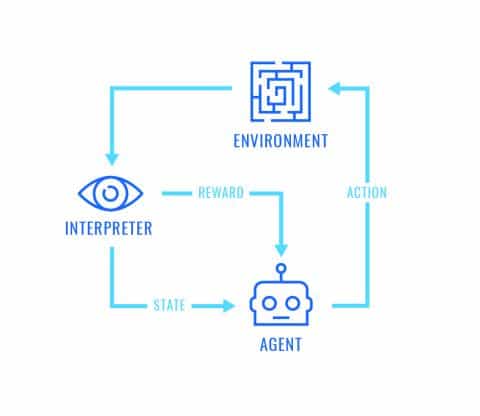
Reinforcement learning (RL) is a branch of machine learning concerned with the process of learning by trying things, receiving a positive or negative reward (feedback), and then modifying behavior to try and maximize cumulative expected reward. Many forms of life learn through RL; for example, a dog can be trained to sit on command by offering treats when she sits, acting as positive reinforcement. Children quickly learn to avoid touching hot things by associating this action with pain, which acts as a strong negative reinforcement signal.
RL applied to artificial intelligence has found remarkable success in recent years due to breakthroughs in both computing resources and algorithm improvements. Graphics Processing Unit capabilities have been improving tenfold every few years. This (combined with the availability of large datasets) has led to massive breakthroughs in the field of deep learning. Fundamental to deep learning is the concept of a neural network: a collection of nodes (neurons) performing operations on an input and returning an output. A deep neural network has many neurons in sequence. Using deep neural networks to approximate the value (output) of taking an action in some state (input) has led to incredibly advanced reinforcement learning agents in multiple domains. Additionally, algorithmic breakthroughs such as experience replay, self-play, and Monte Carlo tree search have pushed improvements specific to RL. The combination of these advancements has created superhuman players of Atari, Go, and Shogi, and a nearly professional DoTA 2 team of bots. There appears to be breakthroughs nearly every week!
What are some of the applications of RL? How is it used at Shield AI?
Some of the leading industrial applications for RL are autonomous driving, factory automation, and resource allocation/scheduling. We consider deep RL at Shield AI for many different applications, including:
- Improved modeling of the robot’s dynamics for state estimation and controls
- Improved modeling of sensor error characteristics
- Improved planning for faster explorations
- Improved environment modeling for even higher fidelity maps and more efficient exploration
- Cooperation among robots in a swarm

Alpha Go must search many layers of this Go game tree before deciding its next move.
Image courtesy of AlphaGo Zero.
What are some of the challenges in RL? What is being done to overcome these challenges?
One of the biggest challenges in RL is acquiring enough data to learn complex behaviors despite potentially sparse reward signals. At Shield AI, we leverage a realistic simulation environment, so that instead of performing a few real flights per hour, we can run hundreds of simulations per hour. Another issue is related to reliability and trust. How can we ensure that a learned policy will always work, and do what we expect of it? There are many steps that can be taken to address risks. The main risk in RL is overfitting the model to the training data and performing poorly in reality. This can be mitigated by keeping the network as small and simple as possible, increasing the amount of training data, making sure the training data is diverse and represents reality well, and using both test data and validation data to explicitly check for overfitting.


